LMmodel
1 简介
目标:给每个句子或者词序列赋予概率
相关应用领域:
机器翻译
如将中文“风很大”翻译成英文,“风”对应的词为“wind”,“很”对应的词为“too”,“very”,“大”对应的词为“big”,"large","high", 这样“风很大”对应的英文就有种可能,通过语言模型就能判断出其中哪种组合可能最大。
拼写检查
语音识别
如输入音节是“zuoye”,其对应的中文可能是“昨夜”,也可能是“作业”,通过语言模型能判断哪种可能最大,如在上下文是“风很大”的情况下,“昨夜”的可能性更大(昨夜风很大)。
2 语言模型建模
2.1 任务
任务1:计算出句子或者词序列的概率
任务2: 计算出句子或词序列下个词的概率
计算以上两个任务的模型均称为统计语言模型,实际上这两个任务是相互关联的,
根据条件概率的定义,可得到以下的链式法则:
e.g.
2.2 估计条件概率
实际中不可能运用该方法,可能的句子太多,语料库永远不可能满足要求
2.2.1 马尔可夫假设
零阶马尔可夫假设(Unigram)
一阶马尔可夫假设(Bigram)
二阶马尔可夫假设(Trigram)
n阶马尔可夫假设(n-gram)
2.2.2 文本生成
2.2.2.1 一般方法
已知条件:
采样生成句子: 对于每个条件概率,有
以概率值采样:
任意给定概率值, 当,取出对应的wordN
重复以上过程直到取出结束符号
2.2.2.2 实际效果
从Unigram Model中生成的文本
fifth, an, of, futures, the, an, incorporated, a, a, the, inflation, most, dollars, quarter, in, is, mass
结论:基本是乱序,无规律的文本
从Bigram Model中生成的文本
outside, new, car, parking, lot, of, the, agreement, reached
this, would, be, a, record, november
结论: 一些短句子的语法结构基本无问题
我们可以延伸至N-gram model,生成的句子会更像自然语言,但这种N-gram model 仍然是由缺陷的,因为语言由长距离依赖问题:
“The computer which I had just put into the machine room on the fifth floor crashed.”
其中crashed出现的概率应当与computer相关,但N-gram model绝对不能覆盖到。
3 N-gram 概率计算
3.1 一元模型先验概率(MLE)
式3.1中代表一个n长的语料库,其中表示其中的词;V指语料库构成的字典,表示每一个词在语料库中出现的概率,故式3.1亦可改写为以下
式3.2中mj表示词wj在句子中出现的次数。
由贝叶斯条件概率公式可得:
极大似然估计是先验概率估计,故和是固定的,问题转化成如下:
其中
使用拉格朗日条件极值,得出结论:
3.2 一元模型后验概率(MAP)
3.3 二元模型概率
例子1:
语料库: I am Sam
Sam I am
I do not like green eggs and ham
例子2:见Language Modeling的PPT第19-20页
由于句子概率普遍偏小,为了防止计算结果下溢,往往以加代乘
4 N-gram语言模型评价
4.1 外在评价
将需比较的模型用于具体任务中(如机器翻译,语音识别),看在任务中的效果
缺点:非常耗费时间,并且需要理解更为复杂的任务。
4.2 内在评价
困惑度(perplexity)
缺点:只在训练集和测试集相似的情况下取得好的评价,通常只适用于小规模试验
降低困惑度等同于提高句子概率,对于Bigram
例子:假设一个句子只包含随机数字,句子的困惑度:
5 语言模型泛化
5.1 平滑问题
N元语言模型只在训练集和测试集相似的情况下起作用,但在实际情况中,往往在测试集中存在OOV words(out of vocabulary words),即会出现测试集中某句子概率为0的情况(如果该句子包含OOV词汇),这样既不符合常理,困惑度也无法计算(分母上会出现零),处理方法:
- 将稀有词汇都用
代替,即出现频率低于某阈值的词,测试的时候OOV words就用 词的概率代替 - 加一平滑,又称Laplace平滑
原估计
Laplace平滑后
但Laplace平滑通常不用于N-gram model中,因为N-gram model中词的统计矩阵太稀疏,通常Laplace平滑可用于文本分类问题中。
5.2 Backoff和interploation
适用于N-gram的平滑方法
有时候一个词依赖于更短的上下文
Backoff:
如果有更多事实的话,使用三元模型,否则使用二元模型或一元模型
Interpolation:
混合使用三元模型,二元模型和一元模型,Interploation的效果一般更好
Interpolation 方法:
如何设置,使用验证集:选择参数,使得验证集上的概率最大:
5.3 极大规模 N-gram model
5.3.1 预处理
只存储文本中出现次数大于阈值的n元组。
5.3.2 优化
采用trie树的数据结构,可以优化时间复杂度为 |V|为字母个数,如英文的话即26个

使用Bloom Filter
利用郝夫曼树对词进行编码,将词作为索引值而不是字符串进行存储,能将所有词编码成包含在2个字节内的索引值
优化概率值存储,概率值原使用的数据类型是(float),用4-8bit来代替原来8Byte的存储内容
5.3.3 平滑方法
stupid backoff方法
6 高级语言模型
判别模型:将n-gram训练的权重用于提高外部任务的性能(语言模型中引入外部任务)
基于语义分析的模型,如下例子
The computer which is bought by her is crashed
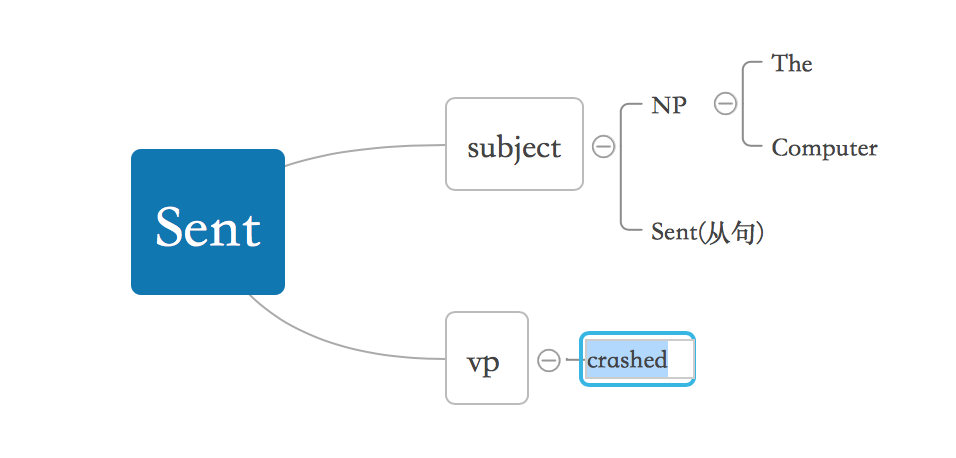
基于语法分析树,crashed和computer的距离很近,而在N-gram中,这中依赖几乎不可能建立
缓存模型
最近使用的词更有可能出现:
7 N-gram模型的缺陷
- 数据稀疏问题:利用平滑技术解决
- 空间占用大
- 长距离依赖问题
- 多义性
- 同义性-如鸡肉和狗肉属于同一类词,应当等于,而在训练集中学习到概率可能相差悬殊
版权声明:本文为复旦nlp组施展根据课堂内容整理的原创文章,转载请注明出处。